





作为一个入门的小型实践,我们将会搭建一个用于识别语音指令的小型神经网络。其本质是输入一个音频序列,然后输出一个类别标签,也就是 Seq2Class。
接下来我们来逐步构建这一模型,以便我们掌握编写一个模型的基本过程,以下的代码块可以按顺序放入一个Jupyter Notebook中执行。
基本设定
首先我们导入需要的模块,然后判断当前的设备,定义需要判断的标签,再定义好标签内容和序号之间的相互映射。
import torchimport torchaudioimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom torchaudio.datasets import SPEECHCOMMANDSimport os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#电脑并不是总有支持CUDA的GPU的,因此在没有CUDA时使用CPU来计算print(f"Using device {device}")
LABELS = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']label_to_index = {label: i for i, label in enumerate(LABELS)}#enumerate()传入一个可迭代的对象作为参数,然后返回元组(序号, 可迭代对象中的一项)组成的列表index_to_label = {i: label for i, label in enumerate(LABELS)}定义Dataset类并实例化Dataset对象
之后,我们需要定义我们自己的Dataset类,在这里我们直接继承torchaudio中自带的SPEECHCOMMANDS类,由于其中自带了数据集,我们就无需再去寻找音频数据了。
通常来说,我们自己的Dataset类都需要定义 __len__(self), __getitem__(self, index) 方法,第一个方法会在调用 len(Dataset) 时候返回数据集的总大小,第二个方法会在调用Dataset[index] 时返回序号对应的对象, 因为数据集内的数据特性不总一致,所以我们需要自行实现这些方法。
实际上,SPEECHCOMMANDS帮我们节省了很多工作,你会发现在下面的代码里我们只定义了__init__(),这是因为其他的两个方法已经被SPEECHCOMMANDS父类定义好了。自行定义Dataset类是编写模型算法的一个重要部分。
我们也没有进行重采样,这一数据集中的数据已经都是16000Hz采样率的了
class SubsetSC(SPEECHCOMMANDS): def __init__(self, subset: str = None): super().__init__("./", download=True) #在这里传入数据集所需要放置的路径,并打开自动下载 def load_list(filename): filepath = os.path.join(self._path, filename) #传入的起始路径与我们得到的_path有关,它是在SPEECHCOMMANDS中定义的 with open(filepath) as fileobj: return [os.path.normpath(os.path.join(self._path, line.strip())) for line in fileobj]
if subset == "validation": #SPEECHCOMMANDS中下载的文件夹里已经包含了训练集,验证集的区分,并且以txt形式放在数据集的根目录下,直接使用即可 self._walker = load_list("validation_list.txt") elif subset == "testing": self._walker = load_list("testing_list.txt") elif subset == "training": excludes = load_list("validation_list.txt") + load_list("testing_list.txt") excludes = set(excludes) self._walker = [w for w in self._walker if w not in excludes]
#过滤出我们需要的标签 self._walker = [w for w in self._walker if w.split(os.sep)[-2] in LABELS]
train_set = SubsetSC("training")val_set = SubsetSC("validation")test_set = SubsetSC("testing")
print(f"Train data size: {len(train_set)}")#可以简单查看一下数据集的长度实例化DataLoader对象
封装从原数据到所用数据的处理程序
我们需要将每个波形都转化为梅尔频谱图,然后再将其送给CNN处理,于是我们封装一下转化为梅尔频谱图的这一过程,不过我们不使用librosa,而是使用torchaudio中实现了的同样功能。
transform = nn.Sequential(#Sequential是torch中的一个容器,可以加入复数个torch处理模块 torchaudio.transforms.MelSpectrogram(sample_rate=16000, n_mels=64), #这一模块用于将波形转换为梅尔频谱图,其中n_mels定义了梅尔标度,用于将频谱分离为均匀分布的频率 torchaudio.transforms.AmplitudeToDB() #上一操作得到的强度是功率, 因此需要转换为分贝).to(device)#这一后缀可以使得处理完的结果被送进指定的RAM,在使用CUDA的情况下,就是送入显存了不过,这并不足以处理所有数据,实际上它一次只能处理一个波形,然而数据中还有标签这样的额外项,并且数据还是按照批次传入的,所以接下来还需要实现一个collate_fn()函数。
实现用于处理单一批次原始数据的函数
之后我们需要为DataLoader实现一个collate_fn()函数,DataLoader类在训练过程中作为一个中间步骤发挥作用,用于将Dataset中的数据处理为若干个Batch的向量再返回,Batch即为批次大小,表示一次处理的数据条数。
在定义一个DataLoader对象的时候,我们向其传入刚刚得到的Dataset对象,批次大小,是否打乱数据集的布尔值,以及collate_fn()对应的函数对象。
一组装在列表中的数据不会自己变成一个Batch,因此我们需要collate_fn(),“collate”意为”校对,整理”。
我们的模型输入是一秒钟音频所对应的频谱图,然而有的音频比一秒长,有的则更短,因此需要先给不够长的音频补上空片段,过于长的音频裁切,得到尺寸刚刚好的波形,即为校对。
然后,我们把所有的波形使用stack()方法堆叠起来,变成一整个批次的波形。再把序列对应的标签也按照波形的顺序排列起来,转换为一个tensor。
最后把打包好的波形传给刚刚的transform对象,就得到了许多梅尔频谱图,就可以传回使用了。
def collate_fn(batch): #batch是一个列表,包含复数个元组(waveform, sample_rate, label, speaker_id, utterance_number) tensors = [] targets = [] for waveform, _, label, *_ in batch: targets.append(label_to_index[label]) #模型不直接使用标签本身,而是使用标签对应的序号 if waveform.shape[1] < 16000: #在小于一秒是补上空音频,大于时裁切 waveform = F.pad(waveform, (0, 16000 - waveform.shape[1])) elif waveform.shape[1] > 16000: waveform = waveform[:, :16000] tensors.append(waveform) #堆叠成batch,形状即为(batch_size, 1, 16000) tensors = torch.stack(tensors).to(device) targets = torch.tensor(targets).to(device) # 提取梅尔频谱特征 melspecs = transform(tensors) return melspecs, targets
batch_size = 128#实例化训练集,测试集,验证集的DataLoader对象train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)一旦实例化了DataLoader对象,我们的数据集就完全地准备好了,我们再进行进一步的工作。
定义模型的架构
之后,就开始定义我们的模型架构。由于我们实际上是将音频当作图片来看待的,所以我们使用基本的卷积网络来构建模型。
在放出代码之前,我们也来介绍一下涉及到的基本算法。
二维卷积
nn.Conv2d(in_channels=a, out_channels=b, kernel_size=c, stride=1, padding=1)看到名字你可能就知道,还存在三维的卷积层,不过不是我们现在要说的
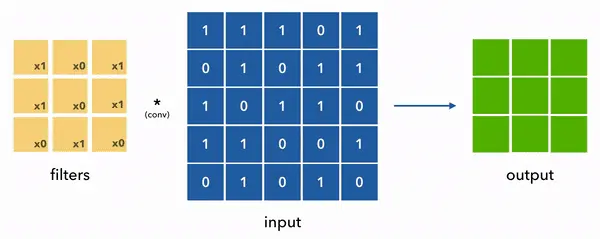
二维卷积层的作用就是提取特征,具体来说是每一个卷积核对应的感受野中的特征。提取特征的方式就是通过将卷积核中的权重值与输入的频谱图的“一小块”进行点积,也就是按位相乘再相加,然后加上偏置项,并且在原输入上滑动地多次进行这一过程,譬如对于两个矩阵
这样我们就能得到每个感受野对应的特征,并且得到一个新的多维矩阵,新的多维矩阵的尺寸是由参数kernel_size, stride, padding共同决定的,kernel_size就是卷积核的大小,stride表示卷积核每次滑动的步长,padding表示在原输入的外围补充0的圈数。这就是卷积层在一个卷积核上做的事情。
决定”一小块”的大小的就是kernel_size,kernel_size越大,神经网络就能感受到更加”大”的特征,但是却也会导致丢失对更”小”特征的感受
一个卷积核就是一个小矩阵,这个矩阵中有需要学习的权重参数,比如图中黄方块里的1和0,实际的权重参数会是更复杂的浮点数
之前的笔记里我们说到过感受野,在下面的图片中你可以更清晰地理解这个概念。可以看到,不论权重多么准确,神经网络始终都是在对一个3x3的区域操作,因此如果有一个特征占的空间很大,神经网络就没法对它进行整体把握
你可能想问,这个偏置项 有什么作用呢?显然在输入全为0而没有偏置项的时候,输出就能只是0,然而这并不符合真实世界中的数据分布,它并不是总过零点的。通过再增加这样一个偏置项作为要训练的参数之一,我们就能平移结果,更好地拟合真实数据。并且,这一偏置项还可以配合之后的ReLU激活函数 (你先别急,之后会讲) ,通过调控数据的正负,来决定神经元被激活的难易程度
你可能注意到我们刚刚说了,这是卷积层在一个卷积核上所做的事情,但实际上一个卷积层当中有复数个卷积核,卷积核的个数由参数out_channels决定。每一个卷积核,都有独立的,需要学习的权重参数和偏置项。
因此,实际上发生在CNN里的事情类似于下图这样,每一个条条就是一个通道,每一个通道都对应一组权重和偏置项

我们最后再发散一下,增加通道数有什么作用呢?一个频谱图里的特征是多样的,包含各种字母的发音,但是一个卷积核,也就是一个通道并没有办法学习那么多特征,因此我们就需要多个通道,来学习多个特征。并且,卷积网络通常是分层使用的,用于让模型可以学习到更高级的概念,例如低层卷积层的卷积核可能学习到一个音节的特征,高层卷积层则能学习到一整个词的特征。
二维最大池化
nn.MaxPool2d(kernel_size=a)二维最大池化层的作用在于压缩特征,并且将细节的特征抽象为更加整体的特征。池化层也有一个滑动的窗口,但是与卷积层不同,这个窗口的滑动方式是前后不重叠的,其大小由参数kernel_size决定。对于每一次停留的窗口,它都会取当前对应部分中的最大值,然后丢弃其他所有的值,把这个最大值作为这一窗口的代表值。
这就使得特征被压缩,并且最强烈的特征得到保留,其他琐碎的部分被抛弃。
二维平均池化
nn.AdaptiveAvgPool2d((x, y))平均池化所作的事情就如同上面的最大池化,只不过它并不取最大值作为代表值,而是取窗口中所有值的和并且取平均,作为这一窗口中的代表值。
在AdaptiveAvgPool2d这一函数中,我们无需指定窗口大小,只需指定期望的输出大小,这个函数会反推出窗口的大小。
在下面的代码中我们令参数为(1,1),就是将所有的特征浓缩为唯一的一个特征,指示音频中出现了哪一个词
线性层
nn.Linear(tensor_length, num_classes)线性层通过将输入的矩阵与权重矩阵的转置相乘,得到了每一条音频对于各个分类的分数,分数越高表示音频越有可能是属于那一个分类的。具体来说,这一过程是这样的,首先我们有输入
这实际上就是一个表格,其中 表示当前批次中第i条语音中,第j个通道所对应的特征的强度,每一行就刻画了一条语音所有特征的强度。
矩阵就是表格,表格就是矩阵!——教我线代的教授
然后我们有权重矩阵,并且将其转置
其中 表示第j个类别中,第i个通道所表示的特征所表示的权重,是要训练的参数,表示这一特征对于这一类别的重要程度。
在线性层中,我们将会进行这一操作
其中 是输出, 为偏置项,是一个尺寸为 的一维向量,在这里会通过广播机制,将这个向量复制为 个相同的向量并且堆叠为尺寸是 的矩阵然后进行运算,与之前讲述过的偏置项作用无异。我们知道其结果为
其中,根据线性代数中的矩阵乘法特性有
表示通道数,我们发现,一条数据中的每一个通道的强度,都会与一个类别中每一个通道的权重按顺序相乘,这就是加权求和呀!因此我们计算的结果就是每一条数据对于每一个类别的分数,分数越高,一条数据就越可能属于那一个类别。
现在我们介绍完了所有涉及到的算法,现在就可以给出代码实现了
定义模型架构
模型的架构是一个Module类的子类,需要在其中定义基本的层,然后在定义用于向前传播的forward方法
class AudioCNN(nn.Module): def __init__(self, num_classes=10): super(AudioCNN, self).__init__() #输入形状为(Batch, 1, 64, 81) self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1) self.pool1 = nn.MaxPool2d(kernel_size=2) #形状 -> (16, 32, 40) self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1) self.pool2 = nn.MaxPool2d(kernel_size=2) #形状 -> (32, 16, 20) self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1) self.pool3 = nn.MaxPool2d(kernel_size=2) #形状 -> (64, 8, 10) #连续进行三次卷积并池化的操作,这样就压缩了尺寸,并且扩大了通道数,提取出了特征 #全局平均池化,解决时间维度可能微小变化的问题,同时也将所有分散的特征集合起来 self.global_pool = nn.AdaptiveAvgPool2d((1, 1)) #形状 -> (64, 1, 1) #分类 self.fc = nn.Linear(64, num_classes) self.dropout = nn.Dropout(0.3) def forward(self, x): x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) x = self.pool3(F.relu(self.conv3(x))) x = self.global_pool(x) x = x.view(x.size(0), -1) #将尺寸为(Batch, 64, 1, 1)的张量展平为矩阵(Batch, 64),因为这时候不再需要后两个维度了 x = self.dropout(x) x = self.fc(x) return x
#然后实例化我们的模型model = AudioCNN(num_classes=len(LABELS)).to(device)#这时如果print模型,会返回模型中的各个层的信息print(model)你可能注意到了我没有介绍其中的dropout,这一个层是用来随机地将给定比例的值设为0的,这样就可以防止模型在学习时死记硬背。
定义训练和测试函数并开始训练
首先我们需要一个损失函数,来评估输出的正确程度,于是我们引入CrossEntropyLoss,这一模块首先会将拿到模型的输出,然后将其使用Softmax函数归一化
归一化就是使得所有分数的和为1,也就是将分数处理为了概率,为什么称为分数呢?请参考之前的部分里对“线性层”的介绍
归一化之后,这一函数会评估模型的输出,如果模型给出的向量中,正确答案的预测概率接近1,那么loss就会很小,反之loss就会很大
然后我们还需要一个优化器,比较常用的是Adam优化器,这是一个用于更新模型内部的参数,也就是之前介绍过的权重的算法,目的是为了让loss越来越小
同时Adam具有自适应学习率,可以更好地迭代模型
同时,你也可以看到一个重要的超参数被传给了Adam,也就是学习率 (Learning Rate),一个很常见的比喻是将寻找loss为0的参数的过程比喻为根据坡度来寻找山谷,坡度也就是求导的结果,这时候,学习率可以看作步幅的大小,如果太大,就会在山坡之间左右横跳,如果太小,则会使得收敛的过程很慢,还可能会陷入局部最优解
局部最优解也就是,比如山坡上有一个小突起,这个小突起同样是中间低两边高的,有时候模型会卡在这里,误以为这里就是最终结果
然后我们就可以开始编写这两个函数了,小细节我以注释的方式给出来,编写完这两个函数,也就可以直接训练了
criterion = nn.CrossEntropyLoss()#这里传入了学习率optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_epoch(model, loader, optimizer, criterion): model.train() running_loss = 0.0 correct = 0 total = 0
for inputs, labels in loader: #优化器的梯度本身是会累加的,也就是每一批新的梯度会和上一次的梯度累加在一起,我们不希望这样,因此可以用这个函数来清零梯度 optimizer.zero_grad()
outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() #这里的backward()的作用就是反向传播,然后计算梯度,这时候pytorch会自动求导,实际上类似于通过两个点来求一个近似的斜率 optimizer.step() #这一步真正地修改了模型的参数,它参考loss.backward()给出的结果,以及学习率,去向可能使loss更小的方向更新每一个参数 running_loss += loss.item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item() #predicted.eq(labels)是一个将预测结果与正确答案进行对比,从而得到的布尔值组成的列表,再加入.sum()就会将布尔值,也就是0和1求和,得到一个一维张量,再进行.item()就将数字从张量里拿出来变为一个数,也就是正确预测的个数
#在这里,我们刚刚将每个Batch的Loss累加起来,现在除以数据的数量,就是平均Loss了 return running_loss / len(loader), 100. * correct / total
def eval_epoch(model, loader, criterion): model.eval() running_loss = 0.0 correct = 0 total = 0
#我们之前说过pytorch会自动求导,但是在验证的时候,我们不需要更新参数,也就不需要求导,因此可以通过这一行来使pytorch不自动求导,就可以节省算力了 with torch.no_grad(): for inputs, labels in loader: outputs = model(inputs) loss = criterion(outputs, labels)
running_loss += loss.item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item()
return running_loss / len(loader), 100. * correct / total
#开始训练,这时候我们定义一下想要训练的epoch数,这里10就够了epochs = 10print("Starting training...")for epoch in range(epochs): train_loss, train_acc = train_epoch(model, train_loader, optimizer, criterion) val_loss, val_acc = eval_epoch(model, val_loader, criterion)
print(f"Epoch {epoch+1}/{epochs} | " f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | " f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%") #返回一下各种数据总是好的,可以让我们看到模型到底有没有长进,实际上也有tensorboard之类更高级的监测模块,不过我们没有使用保存权重
训练完的权重是显然需要保存的,我们可以很简单地完成这一步
哈哈,没有几千字长的算法介绍了,你轻松,我也轻松,都好,都好啊!
#定义保存路径model_save_path = "audio_cnn_weights.pth"
#提取模型中的所有可学习参数(权重和偏置)#model.state_dict() 是一个包含所有参数的 Python 字典torch.save(model.state_dict(), model_save_path)
print(f"Saved weight to: {model_save_path}")验证与推理
直接使用我们的eval_epoch函数就可以验证最终的准确性了
而对于推理,我们需要先有一个推理函数。对于推理函数,我们首先需要通过model.eval()来将模型转换到评估模式,这会关闭模型里的Dropout操作
还记得Dropout吗,它会将一些结果置0,在训练时它有帮助模型变得更好,但在推理时我们不希望它来屏蔽任何的结果
由于现在我们需要实际使用模型了,输入的音频不一定是16000Hz的,所以就需要进行重采样。并且,输入的音频可能是双声道而非单声道,这样的话输入的波形的尺寸就是(2, 16000)了,而尺寸错误会导致报错,所以需要将声音处理为单声道,我们直接使用对张量的.mean()方法,将每一个采样点处的左右声道求平均,变为一个声道
同样的,由于模型只能输入定长的音频,需要对音频进行补零或者切割
# 在测试集上测试test_loss, test_acc = eval_epoch(model, test_loader, criterion)print(f"Final Test Accuracy: {test_acc:.2f}%")
def predict_audio(model, waveform, sr): model.eval() with torch.no_grad(): target_sr = 16000 #在采样率不同的时候重采样 if sr != target_sr: resampler = torchaudio.transforms.Resample(sr, target_sr) waveform = resampler(waveform)
#在非单声道的时候将声道合并 if waveform.shape[0] != 1: waveform = waveform.mean(dim=0, keepdim=True) #修补长度 if waveform.shape[1] < 16000: waveform = F.pad(waveform, (0, 16000 - waveform.shape[1])) elif waveform.shape[1] > 16000: waveform = waveform[:, :16000]
#添加Batch维度并移动到设备 #unsqueeze()是一个对张量的操作,可以增加维度,其参数是增加维度的位置,这一张量原本的尺寸是(1, 16000),因此一共有三个地方可以增加维度,从前到后分别用0,1,2表示,这样就能保证输入的波形形状是正确的 waveform = waveform.unsqueeze(0).to(device) # (1, 1, 16000)
#提取频谱图 melspec = transform(waveform)
#模型预测 output = model(melspec) #之前在说CrossEntropyLoss的时候说过了Softmax,现在我们没有标准答案,也就不需要Loss函数了,不过它也带走了Softmax函数,因此我们也得加上一个Softmax来使得输出变为概率 #使用softmax的时候需要指定对哪个维度进行操作 #还记得模型的输出吗,是(Batch, Number of classes),在这里是(1, 10),第二个维度才是需要softmax的,又由于计算机从0开始数数,所以是维度1 probabilities = F.softmax(output, dim=1)
predicted_idx = torch.argmax(probabilities, dim=1).item() confidence = probabilities[0][predicted_idx].item()
return index_to_label[predicted_idx], confidence然后就可以开始愉快地推理了,我们可以取测试集的一条进行尝试
sample_waveform, sample_rate, true_label, *_ = test_set[0]predicted_label, conf = predict_audio(model, sample_waveform, sample_rate)
print(f"True Label: {true_label}")print(f"Predicted: {predicted_label} (Confidence: {conf*100:.2f}%)")也可以自己录制一条声音尝试
#显然你的电脑上不可能有这一条音频,因此要把路径换成你的,并且记得改掉单反斜杠wav, sr = torchaudio.load("I:\\AudioResources\\yes.wav")predicted_label, conf = predict_audio(model, wav, sr)
print(f"Predicted: {predicted_label} (Confidence: {conf*100:.2f}%)")加载权重
有可能我们有时候想要直接加载训练好的权重,那怎么办呢?这时候就需要用到之前保存的.pth文件了,只需使用torch.load()方法即可
#重新实例化一模一样的模型结构#你需要确保 AudioCNN 类的定义在这段代码块之前已经运行过,否则这个类是不存在的loaded_model = AudioCNN(num_classes=len(LABELS)).to(device)
#从硬盘读取权重字典,并注入到模型中#map_location非常重要,它能确保如果你的模型是在 GPU 上训练的,但现在你想在没有 GPU 的普通电脑上推理,它会自动将其映射到 CPU。#同样的,可能你的权重路径不长这样,那么就需要改一下下面的路径参数weights = torch.load("audio_cnn_weights.pth", map_location=device)loaded_model.load_state_dict(weights)
#切换为评估模式,我们之前已经介绍过,这会关闭Dropout并冻结BatchNorm等层loaded_model.eval()
print("Loaded weight")结语
至此,我们已经完成了一个模型从建立框架开始,经历训练,一直到推理的全过程,可喜可贺,可喜可贺。掌握了这一些内容,在面对现在的,显著地更加先进与复杂的模型时,也可以将其进行拆解并且知道每一步在做什么了。同样,你也可以开始自己的研究,确立一个属于自己的模型架构,然后试着创造一些历史了 (哇呼!创造历史!) 。
我们的两只鸽子前后花费了半个月的时间来手敲这一篇教程,在敲到这里的时候,他已经快燃尽了 (燃尽了喵) ,并且开始敲一些不知所谓的内容 (不知所谓喵),如果你觉得在读了这篇教程后离模型算法工程师更近了一步 (一小步也可以,拜托),还请到两只鸽子的哔站主页点一下关注,投一点币,甚至充个电吧,非常感谢~。
部分信息可能已经过时